

安装教程
1、从本站下载数据包并解压,选择同意协议然后点击next。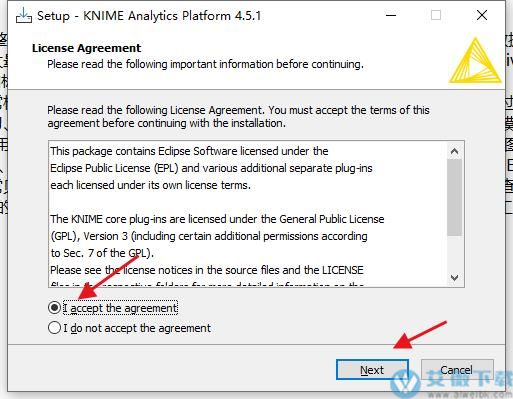
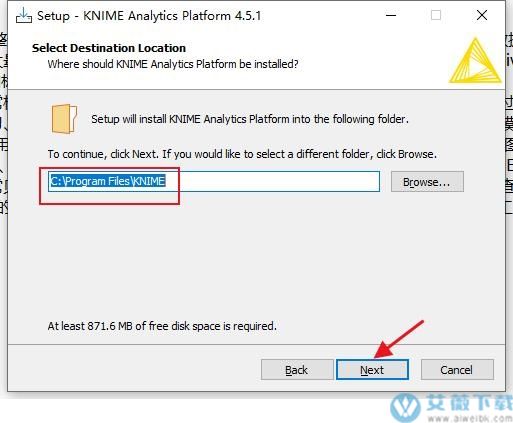
2、设置安装目录然后点击next。
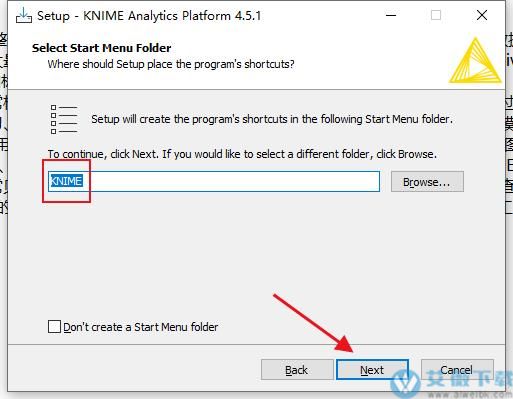
3、设置开始文件夹,然后点击next。
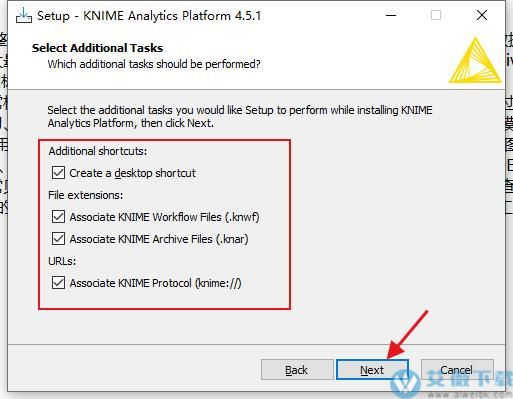
4、选择需要的选项,然后点击next,
5、点击“install”。
6、软件正在安装,请耐心等待。
7、安装完成。

软件功能
1、构建端到端的数据科学工作流程用直观的拖放式图形界面创建可视化工作流,不需要编码。
将不同领域的工具与KNIME原生节点融合在一个工作流中,包括R和Python的脚本,机器学习,或与Apache Spark的连接。
从2000多个模块("节点")中选择,建立你的工作流程。对你的分析的每一步进行建模,控制数据流,并确保你的工作始终是最新的。
快速启动和运行。从数百个公开可用的工作流程范例中选择一个,或使用集成的工作流程教练来指导你建立你的工作流程。
2、混合来自任何来源的数据
打开并结合简单的文本格式(CSV、PDF、XLS、JSON、XML等)、非结构化数据类型(图像、文件、网络、分子等)或时间序列数据。
连接到大量的数据库和数据仓库,整合来自Oracle、Microsoft SQL、Apache Hive等的数据。从HDFS、S3或Azure加载Avro、Parquet或ORC文件。
从某推、AWS S3、Google Sheets和Azure等来源访问和检索数据。
3、塑造你的数据
得出统计数据,包括平均值、量值和标准差,或应用统计测试来验证一个假设。将降维、相关分析等整合到你的工作流程中。
在您的本地机器、数据库内或分布式大数据环境中对数据进行汇总、排序、过滤和连接。
通过规范化、数据类型转换和缺失值处理来清理数据。通过离群值和异常检测算法检测超出范围的值。
提取和选择特征(或构建新的特征),为机器学习准备你的数据集。操作文本,在数字数据上应用公式,并应用规则来过滤掉或标记样本。
4、充分利用机器学习和人工智能
使用先进的算法,包括深度学习、基于树的方法和逻辑回归,为分类、回归、降维或聚类建立机器学习模型。
通过超参数优化、提升、装袋、堆叠或构建复杂的组合来优化模型性能。
通过应用性能指标验证模型,包括准确度、R²、AUC和ROC。进行交叉验证以保证模型的稳定性。
直接使用验证过的模型进行预测,或使用业界领先的PMML,包括在Apache Spark上。
5、发现和分享洞察力
用经典的(柱状图、散点图)以及高级的图表(平行坐标、太阳花、网络图)来可视化数据,并根据你的需要进行定制。
在KNIME表中显示有关列的汇总统计,并过滤掉任何不相关的东西。
将报告导出为PDF、Powerpoint或其他格式,用于向利益相关者展示结果。
将处理过的数据或分析结果存储在许多常见的文件格式或数据库中。
6、根据需求扩大执行规模
建立工作流程原型,探索各种分析方法。检查和保存中间结果,以确保快速反馈和有效发现新的、创造性的解决方案。
通过内存流和多线程数据处理来扩展工作流程的性能。
在Apache Spark上锻炼数据库内处理或分布式计算的能力,以进一步提高计算性能。
软件特征
1、新的日期和时间集成现在KNIME有完全修订的节点来处理日期和时间数据类型。这些包括更细化的数据类型,如本地日期和时间、持续时间,以及更好地处理时区。
2、与H2O机器学习库的集成
H2O是一个开源的机器学习和预测分析库,非常注重可扩展性和性能。这个KNIME-H2O集成的第一个版本为H2O的机器学习和评分的功能集合提供了该软件节点。
3、该软件个人生产力现在是该软件分析平台的一部分
该软件个人生产力套件现在是免费和开源的,与该软件分析平台的其他部分一样。你可以使用本地Metanode模板,在另一个该软件工作流中调用本地工作流,设置你自己版本的该软件工作流教练,并使用工作流差异来显示工作流或同一工作流的不同版本的差异。

4、包裹元节点的综合视图
包含快速表格和/或JavaScript视图的封装元节点的默认视图现在显示与用该软件网络门户打开封装元节点时的视图相同。这为该软件的交互式数据分析提供了许多新的可能性。为了获得最佳的性能和互动性,我们建议你将该视图配置为使用你本地安装的Chrome浏览器。

5、新版本的Python集成
在该软件实验室有一个新版本的KNIME-Python集成。新的实现同时支持Python 3或Python 2,这将使我们能够继续进行未来的改进。
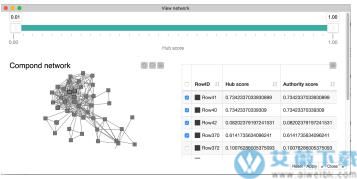
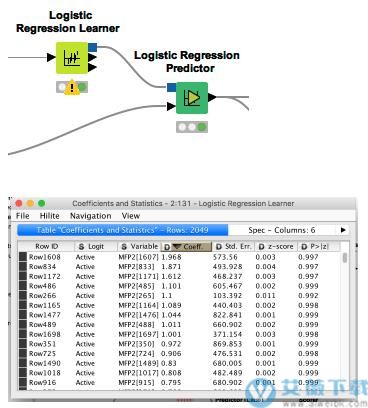
6、逻辑回归节点的可扩展性更强,速度更快,并支持正则化
我们已经完全重写了Logistic回归学习器的后台代码。使用 "SAG "求解器,该节点现在的速度快了很多,而且支持更大的数据集,包括行数和特征。它还支持正则化,并提供了一个新的输出表,其中有关于计算系数的详细统计数据。
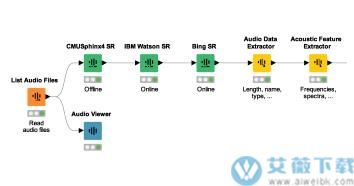
7、音频和语音识别节点
现在该软件可以听你说话了! 在这个版本中,我们增加了一些节点,允许你在该软件中处理音频文件,并使用一些语音识别工具。但这不仅仅是为了语音:我们还内置了从这些音频文件中提取每分钟节拍和频率分布等特征的功能。
8、JavaScript视图
我们为该软件增加了三个新的JavaScript视图。
网络查看器:用于查看有向和无向的网络。它支持多种布局和格式化选项。
旭日图:对于事件序列(如点击流)是非常有用的可视化,我们还发现了一些其他有趣的东西,你可以用这个来做。
流图/堆积区域图:一种显示多个数据序列在特定时间段内的演变的方便方法
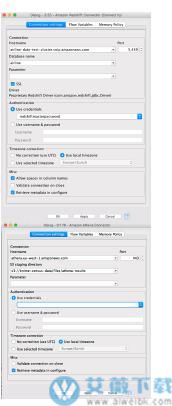
9、新的云连接器
有两个新的数据库连接器,允许你使用该软件的标准数据库节点与亚马逊网络服务托管的数据库一起工作。亚马逊Redshift连接器允许你利用亚马逊的可扩展和完全管理的数据仓库解决方案,而亚马逊Athena连接器让你查询存储在S3中的文件集,就像它们被加载到关系仓库中一样。我们还提供了节点,让你可以轻松地创建和销毁Redshift集群,所以在云端启动一个管理仓库来运行一些实验,完成后再清理仓库,这些都可以在该软件分析平台内完成。
10、"部署到服务器 "和 "在WebPortal中打开 "菜单项
现在从该软件分析平台内部使用该软件服务器变得更加容易。你可以使用 "部署到服务器 "选项,从你的本地工作流仓库部署工作流到该软件服务器,只需一次点击。此外,你可以通过该软件资源管理器的上下文菜单,为存储在该软件服务器上的工作流打开WebPortal页面。

11、分布式执行器的预览
我们正在努力扩展该软件服务器,以支持使用多个分布式执行器执行工作流,而不是完全依赖服务器本身的计算能力。我们认为这是一个重要的新功能,并希望从该软件服务器客户那里得到早期反馈,因此我们将提供几个预览版。第一个预览版已经准备就绪,请与你在该软件的联系人联系,了解如何获得访问权限。

12、常见大数据文件格式的云连接器
Spark IO节点现在支持从云存储系统(如Amazon S3和Azure Blob Store)读取和写入常见的大数据文件格式。
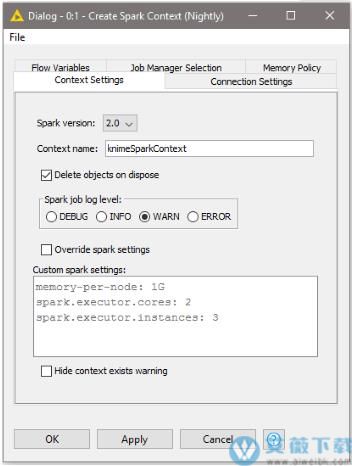
13、支持Spark 2.0
KNIME Spark Executor现在支持创建和管理Spark 2.0作业。
随着对Spark 2.0的支持,我们还引入了新的Spark Java Snippet节点,允许专家用户使用新的Spark DataFrame API编写自己的Spark作业。
请注意,由于Apache Spark中的一个错误,Hive到Spark和Spark到Hive节点在这个版本中不能用于安全的集群。我们正在研究一个解决方案,预计将在今年晚些时候发布。
软件特征
1、采用完全图型化的操作方式2、支持各类方式的数据加载,包括文件、数据库等
3、支持各类数据处理方式,包括按列(如分拆、合并等)、按行(过滤、变形)、矩阵(转置)和PMML(字段投影、一对多、多对一、正态化、反正态化等)
4、支持各类数据视图,如点图、直方图、饼图、分布图
5、支持假设检验和回归方法
6、支持决策树、贝叶斯、聚类、规则推导、神经网络等挖掘方法
7、支持流程控制














