提取码:3fic
安装破解教程
1.下载安装包,解压缩并运行安装,点击下一步

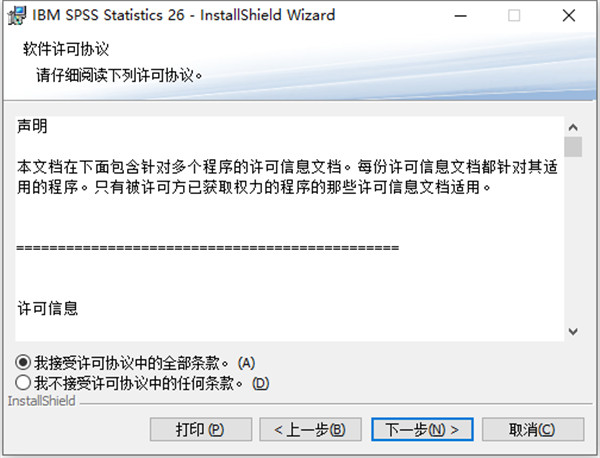
2.勾选我接受许可协议中的条款
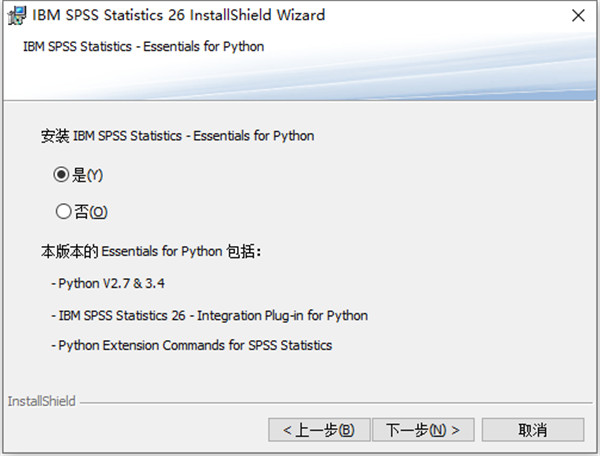
3.选择是否安装Esseontials for Python,自行选择安装即可
4.阅读软件许可证协议,勾选我接受
5.选择软件安装位置,点击更改可自行更换安装路径
6.点击安装即可
7.正在安装中,请耐心等待一会
8.安装成功,将立即启动软件的勾选去掉,点击完成退出安装向导
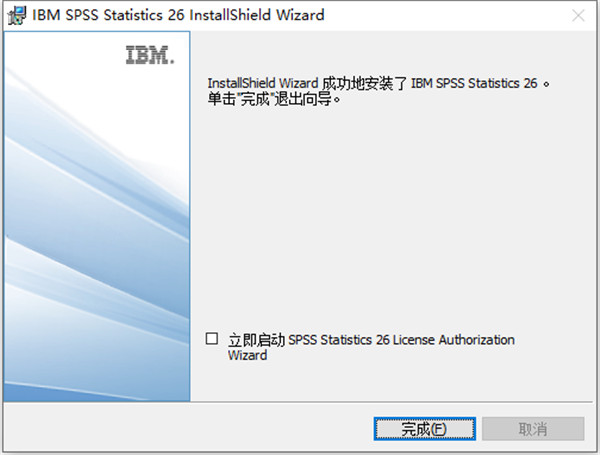
9.退出安装向导后,再运行软件即可免费使用了,如果许可信息提示“已到期,并且将很快停止工作”忽略即可
应用亮点
1.分位数回归
在标准“最小二乘”回归中,模型预测基于单个回归线。该线可用于估计因变量的平均值,由在独立(预测变量)变量的给定值处的线聚类点表示。
2.ROC分析
新的ROC程序可以更容易地评估预测分类模型的准确性和性能。ROC(接收者操作员特征)分析特别关注模型的分类准确性,特别是关于准确分类(称为真阳性和真阴性)与不准确预测(假阳性和假阴性)之间的关系。这些通常由ROC曲线表示,该曲线在不同阈值设置下绘制真阳性率(TPR)与假阳性率(FPR)。新的ROC分析程序还包括精确回忆(PR)曲线,并提供用于比较从独立组或成对受试者生成的两条ROC曲线的选项。
3.贝叶斯统计
spss statistics 26还包括其贝叶斯统计程序套件的增强功能。
4.单向重复测量ANOVA
重复测量增强允许分析人员采用贝叶斯方法来比较不同时间点或条件下同一受试者的给定因子的任何变化。假设每个受试者对每个时间点都有一次观察。
5.一个样本二项增强
在这里,用户可以应用贝叶斯二项式检验来尝试确定两组之间观察到的比率与群体中的假设比例相同的可能性。
6.一个样本泊松增强
与前面的过程一样,除了这里用户可以将它们的数据与它与泊松分布的拟合程度进行比较。这些分布对于诸如事故或保险索赔等罕见事件是有用的建模。当在泊松分布上绘制贝叶斯统计推断时,使用Gamma分布族内的先验共轭。
7.可靠性分析
对SPSS Statistics的可靠性程序进行了一些额外的增强。可靠性分析现已更新,为Fleiss的Multiple Rater Kappa统计数据提供了选项。在将分类评级分配给多个项目或对项目进行分类时,在评估固定数量的评估者之间的一致性的可靠性时,通常采用这种技术。这与其他kappa值(例如Cohen的kappa)形成对比,后者仅适用于最多两个评估者之间的协议评估。
8.程序和脚本改进,spss statistics 26包含对现有过程和脚本命令的一些增强功能,因此您可以对数据应用更丰富的分析。
功能特色
1.全面的统计工具
在一体化的集成界面中工作,运行描述统计、回归分析、高级统计等等。在单一工具中即可创建可立即发布的图表、表格和决策树。
2.与开放源码集成
通过专门扩展,利用 R 和 Python 增强 SPSS Syntax。利用我们的扩展中心提供的 130 多项扩展,或者构建您自己的扩展并与同行共享,以创建个性化解决方案。
3.轻松进行统计分析
使用简单的拖放界面来访问各种功能,并跨多个数据源工作。此外,灵活的部署选项支持您轻松购买和管理软件。
4.数据准备
轻松识别无效值,查看缺失数据的模式,汇总变量分布,并使用为名义属性设计的算法。
5.查看定价并购买
创建更可靠的模型,测试其稳定性,并可靠地估计人口参数的标准误差和置信区间。
6.高级统计信息
分析具有唯一特征的数据,描述因变量和自变量之间的关系,并分析事件历史记录和持续时间数据。
7.回归
预测包含多个类别的分类结果,构建非线性关系模型,并从数十种可能性中找到最佳预测变量。
8.定制表格
汇总相关数据,以演示质量的生产就绪型表格呈现分析结果。您还可以将结果导出到 Microsoft® Office 应用程序中。
9.缺失值
检查数据,发现缺失的数据模式,然后通过统计算法估算汇总统计并插补缺失值。
10.类别
直观呈现并探索复杂的分类、数字和高维数据,并使用双标图、三标图和感知图来揭示隐藏的关系。
11.复杂样本
通过将样本设计融入至调查分析中,计算复杂样本设计中的统计信息和标准误差。
12.联合分析
通过基于单独的特性对消费者的决策流程和价值进行建模,更准确地了解消费者的喜好、权衡取舍及价格敏感性。
13.准确测试
分析数据库中的偶发事件,或更准确地使用少量样本。30 余项准确测试有助于分析导致传统测试失败的数据。
14.预测
无论数据集大小或变量数目多少,都能快速可靠地预测未来状况,同时高效地更新和管理预测模型。
15.决策树
创建分类和决策树,帮助您更好地识别群组、发现各个群组之间的关系,并预测未来事件。
16.直接营销
执行最近购买时间、购买频率和总购买金额 (RFM) 及集群分析、潜在客户概要分析、邮政编码分析、倾向性评分和控制包测试。
17.神经网络
探究数据中微妙或隐藏的模式,发现数据中更复杂的关系,进而生成性能更佳的预测模型。